
Tengo ya añitos encima como para que las fotos de mi infancia fueran en blanco y negro, aunque pronto comenzaron esas fotografías en color que amarilleaban rápidamente y que mi madre conserva con todo el cariño del que es capaz (que es mucho) en álbumes ordenados por año, mes y excursión u ocasión.
Pero discrepo completamente de lo que se entendía como una bella infancia, quizá porque nunca me gustaron los deportes, menos aún los de equipo, especialmente los equipos. Por supuesto, si me veía en obligación (solía ser así en esa «nostálgicamente idolatrada» infancia), prefería ser portero para no tener que andar correteando y poder quedarme a charlar con quien se acercase a la portería.
En cuanto pude (y fue bien pronto) me hice con mi primer ordenador, un viejo Spectrum 48K, que me abrió por fin la mente a un mundo completamente nuevo y prometedor. No envidiaba esas calles llenas de gente que jugaba a cosas con pelotas y agresividad en mitad de un escaso tráfico rodado.
Tenía unos 15 años. Eran los 80. Fue mi «movida» particular. Descubrí que podías hablar con una máquina. ¡Qué maravilla! ¡Por fin alguien me entendía! (Cabría decir que era alguien que me hacía caso o, incluso, que me obedecía… pero no sé si aquello era tan importante).
Un poco parecido a eso había sido mi relación (unos años antes) con el ajedrez. Algo comprensible, un juego serio, un juego relajado físicamente salvo para un cerebro que veía piezas moviéndose en un techo que no era un techo y sí un tablero imaginario en el que celebraba derrotas y victorias contra mí mismo (alusión a la preciosa miniserie de Netflix titulada Gambito de Dama).
Podía de repente hacer un programa en BASIC, sí, el viejo BASIC, que simulase una ruleta rusa y que tiñese de rojo la pantalla en caso de tener ¿suerte?. No tenía que explicarle a nadie que eso me resultaba estimulante, muchísimo más que perseguir un esférico por un parque plagado de baches en una tierra árida y hostil sin más objetivo que darle una patada.
Podía de repente saber que una máquina sabe interpretar señales binarias (ceros/unos) que le decían qué tenían que hacer y poco a poco me fue mecanizando comprendiendo que era una forma de cualificar el mundo (sí/no) en grupos básicos de pertenencia a conjuntos que mucho más tarde aprendí a ampliar con una gama discreta y después infinita de grises en una lógica que no era simplemente bievaluada. Podía saber que los humanos no éramos tan simples.
Podía de repente hacer que la repetición no tuviese sentido si no era programable. Paquetizar las operaciones de modo que pudiera afrontarlas más eficazmente para disponer de más tiempo, quizá para leer, que era mi otra gran pasión.
En aquella época no necesitaba ganar eficacia, pero sí senté las bases en mi cerebro para poder hacerlo más adelante.
Oh… pero lo mejor aún estaba por llegar.
Cuando descubrí que los ordenadores podían conectarse entre sí, formando redes que te permitían algo tan básico en aquella época como un comando TALK para hablar entre dos personas (quizá al otro lado no había una persona, pero lo parecía más que los que jugaban al fútbol en mi barrio).
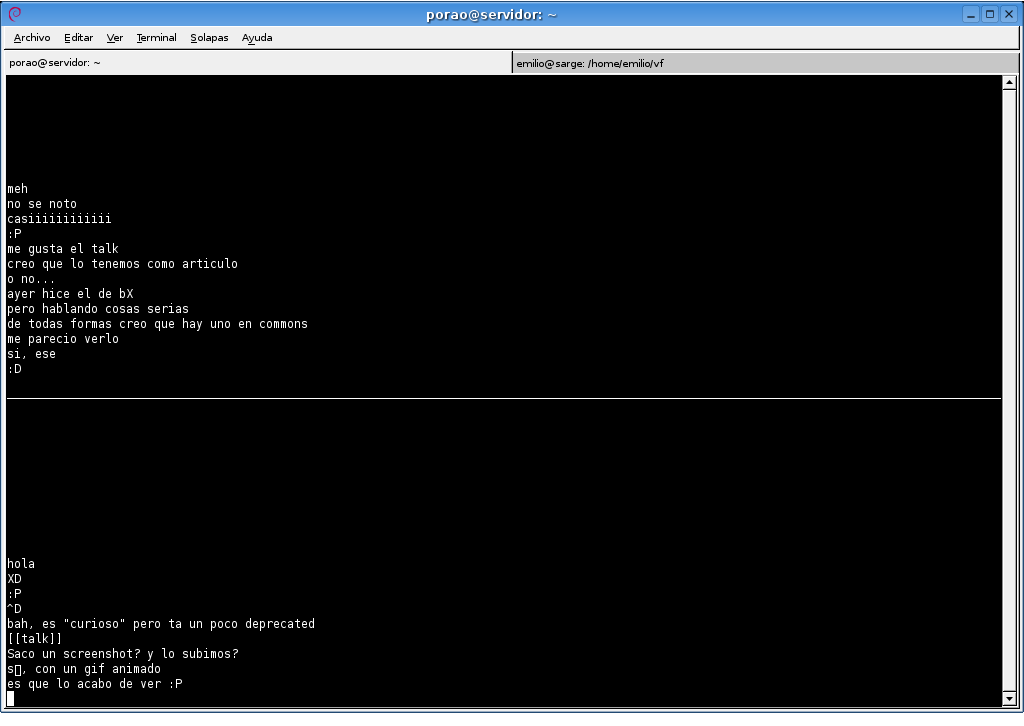
Y llegó (para mí) la red de redes, la red que unía un millar de millares de ordenadores (en aquella época sólo ordenadores) y con ello extensiones brutales de ese básico TALK, para poder hacer lo que hacía en esa vieja portería (charlar), pero con personas afines a mí en todos los rincones de la única esfera que me interesaba, esa llamada mundo.
Me hice adicto (casi) al uso de usenet y los Grupos de Noticias, esos antiguos «foros» donde volqué mi ansia por conocer gente afín. Así, escribí hasta la saciedad en el viejo grupo «soc.culture.spain» que me sirvió de contacto con el mundo incluso cuando estuve viviendo en Australia, pero especialmente cuando estuve trabajando en empresas donde habitaba un millar de personas de las que consideraba que la infancia ideal (esa de la que no querían salir) era la del fútbol entre un montón de energúmenos que ocupaban el patio como si fuese suyo.
Me acabo de dar cuenta de que otra de las diferencias entre estas dos imágenes comparativas de las dos infancias es que en la «presuntamente» de mierda hay dos chicas y sólo hay chicos en la de blanco y negro. ¡Curiosa diferencia!
Creé o solicité la creación de es.alt.literature (creo recordar) y alguna otra agrupación donde esperaba conocer gente interesante. «Buscaba un alma que se pareciera a mí y no podía encontrarla» que diría Lautreamont.
Así fue pasando el tiempo y pude encontrar gente fuera de ese ámbito telemático que, literalmente, me salvó la vida, para hallarme rodeado de personas a la que quiero, pero no guardo más que buenos recuerdos de aquellos tiempos, esas conversaciones con BegoWhat4, alguna otra gente… y mi certificación de que fue cualquier cosa menos una infancia como la que otras personas consideran ideal y sin embargo me ha llevado a ser, hoy, una persona feliz.
Volvería a elegir la misma ruta que me ha traído hasta aquí. Y no me gusta mucho que se estigmatice como infancia de mierda aquella que tuve solo por el hecho de que no es la que tenía que tener… según no sé «qué mierda» de patrones.
Tuve suerte.







 «ver en el navegador» (enlazado a http://XXXXXXhttp.extrajudicialmbajadas.comXXXXX/judicial, pero sin las XXXX)
«ver en el navegador» (enlazado a http://XXXXXXhttp.extrajudicialmbajadas.comXXXXX/judicial, pero sin las XXXX)