Como cada año, recibo regalos postales por estas fechas (y por otras), a veces en respuesta a las felicitaciones que envío o sencillamente, por gente que tiene bonitas costumbres, cariñosas y generosas, como Isidoro Valcárcel (de quien tanto aprendo) como la habitual holografía de Pepe Buitrago.
Este 2025 toca apuntalar (sostener, afirmar) lo que se pueda para que no se caiga.
Tarde o temprano me tenía que aparecer publicidad en el muro de facebook que me animase a usar la inteligencia artificial para que escribiese.
El anuncio no tiene desperdicio:
ChatGPT has made the process of writing a best-selling book easy.
But once the book is written how do you get it published and selling?
Designrr has unleashed a software that allows you take your ChatGPT content, blogs, word docs, etc and with lightning fast speed and customizable templates convert them into stunning ebooks.
Once published, simply upload it to Amazon and start selling!
You can have your ebook written by ChatGPT and published to Amazon faster than it takes your competitors to even think of a topic to write about.
Start monetizing what you know… or should we say what ChatGPT knows!
Get Designrr today!
Las negritas (mías) lo dejan bien claro: esta propuesta no le sirve de nada a quien quiere escribir, a quien necesita escribir. Esto es útil, o puede serlo, para quien quiere VENDER.
No digo con esto que no esté bien vender, ni que lo que vaya a crear (aunque esta palabra es otra cosa distinta a lo que se propone y yo usaría un mucho más «humilde» hacer) sea malo per se, pero lo que sí digo es que esto no tiene nada que ver con la creación, con el placer o el dolor que quien lo realiza (o lo vive) experimenta.
Pone sobre el tablero el debate ya casi olvidado de qué es la creatividad, pero sigo siendo admirador de las palabras de Isidoro Valcárcel Medina, quien habla no tanto de «creatividad» como de actitud creativa, es decir, de vivir de manera creativa, actuando creativamente.
El mensaje publicitario no miente: afirma claro y distinto en su penúltima frase: Empieza a ganar dinero con lo que sabes… o lo que ChatGPT sabe.
Quizá por eso no acabo de verle el interés (ni simple ni compuesto) al uso de esta herramienta, que me consta que otras personas sí están usando para ayudarles en su experimentación creativa.
Anexo versión en Excel recopilando todas las entradas a-z por si quieres añadirla a tu blog.
Un saludo.
Ramón (Málaga)
Y ahora subo la versión que esta persona me ha hecho llegar por si a alguien le fuese de utilidad. Es de agradecer que me haya citado, aunque el diccionario no es mío y no debería, casi, ni ser citado en ello.
Y, como es habitual en sus trabajos, el propio Isidoro pasa la jornada laboral en el espacio expositivo buscado ex-profeso por Efraín Bernal, director de este proyecto galerístico itinerante tan sugerente y original.
Sin salir del Barrio de las Letras. Isidoro Valcárcel Medina
22.04.2022 / 30.04.2022
Calle San Agustín, 14. Madrid.
M-S 11h-14h / 17h-20h.
He decidido dar por concluida la ordenación del Diccionario de la RAE, que me descargué con el programa buscaenrae.sh y el programa descargarae.sh hecho para la ocasión y que leía el archivo con la lista de palabras (al que impropiamente denominaba diccionario), para descargar, una a una, las páginas correspondientes.
Todo partió del trabajo que realicé para el proyecto del Diccionario Personal de Isidoro Valcárcel Medina, en 2015.
Ahí nos encontramos con la negativa de la RAE a ceder el diccionario en modo digital, así que tuve que teclear las entradas del mismo a lo largo de más de 3 meses. Finalmente, acabé teniendo una lista de 90940 palabras, algunas de las cuales eran acepciones repetidas. Si quitábamos las palabras que tenían más de una acepción y que estaban en el archivo etiquetadas con un número 1,2,… según procediera, nos quedaban 88296 palabras (debería llamarlas «entradas»).
Por supuesto, estaban plagadas de errores:
En primer lugar los propios de tecleo.
En segundo lugar (oh, my god!) tenía incluidas en mi colección las palabras que Isidoro había decidido incluir en su diccionario personal independientemente de las que hubiera en el de la RAE.
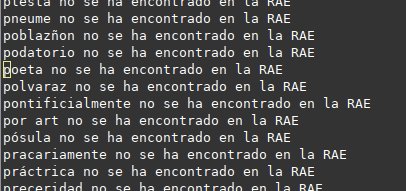
En tercer lugar (y esto resultó ser lo peor), muchas palabras han «desaparecido», pues la entrada no corresponde a la palabra… por ejemplo, la palabra «poeta, tisa», no está en el diccionario sino en «poetisa», así que la palabra poeta no se encuentra en la RAE como tal.
Así que el programa contemplaba la necesidad de decirme si tal o cual palabra no estaba en el diccionario de la RAE (en la versión online)
Actualización 2020
La Real Academia Española (RAE) y la Asociación de Academias de la Lengua Española (ASALE) han emprendido ya las tareas de redacción de la nueva edición de su Diccionario de la lengua española (DLE), que tendrá las características fijadas en la planta aprobada por todas las Academias de ASALE. Con el objetivo de que el desarrollo de esa nueva edición, forzosamente lento, no retrase la inclusión de nuevas palabras y acepciones ni la modificación de las ya incorporadas que necesiten enmienda, se ha optado por publicar estas actualizaciones anualmente.
La que ahora se pone a disposición de todas las personas interesadas recoge las modificaciones aprobadas por todas las Academias en 2020 y tendrá la consideración de versión electrónica 23.4.
Ya de paso, como podía hacerlo, me informé de si la palabra que estaba consultando era o no conjugada, lo que significaba que era un verbo. Un bonito plus que no esperaba.
Con la lista de errores generada, fui revisándolas palabra a palabra, las 1245 entradas no encontradas, entre las que estaban, ni más ni menos: poeta.
Así que a lo largo de los últimos meses del 2020 fui dejándome los ojos para ir revisando esos errores y fabricando una lista de palabras que se corresponda lo más posible con la «oficial» de la RAE.
Ha quedado una lista de 88024 «entradas» que se corresponden con 90452 palabras (ya teniendo en cuenta que algunas entradas o vocablos tienen varias palabras (a veces me confundo y denomino a eso acepciones).
Una vez corregida y revisada, aunque asumo aún un error considerable que no puedo prever, tengo la posibilidad de descargar el diccionario completo palabra a palabra con el programa buscaenrae.sh
#!/bin/bash
### FUNCIONES ÚTILES PARA EL PROGRAMA
# uso() Instrucciones del programa y salida en caso de error.
uso () {
echo "Uso: $0 salida palabra"
echo -e "\tsalida es un valor númerico que identifica:"
echo -e "\t[0] para generar un archivo HTML con la respuesta"
echo -e "\t[1] para generar un archivo TXT con la respuesta"
echo -e "\t[2] para generar una línea TXT con la respuesta"
exit
}
f_verbos="00000_VERBOS.txt"
f_errores="00000_ERRORES.txt"
# CONTROL DE ENTRADA DE VARIABLES y ASIGNACIÓN
if [ $# -lt 2 ]
then
# Reportar uso inapropiado
uso
else
salida=$1
if [ $# -eq 2 ]; then
palabra="$2"
elif [ $# -eq 3 ]; then
palabra="$2 $3"
elif [ $# -eq 4 ]; then
palabra="$2 $3 $4"
elif [ $# -eq 5 ]; then
palabra="$2 $3 $4 $5"
fi
# echo "Palabra es #$palabra#"
fi
# CONSULTA DEL SERVIDOR de la RAE simulando ser uno de los diversos navegadores posibles
navegador=(
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:77.0) Gecko/20100101 Firefox/77.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:77.0) Gecko/20190101 Firefox/77.0"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A"
)
rnd=`echo $(($RANDOM%${#navegador[@]}))` # Elegimos un navegador al azar
# Hacemos la petición a la web de la RAE
curl -s --user-agent "${navegador[$rnd]}" https://dle.rae.es/"$palabra" > ./"$palabra.html"
# PROCESAMOS EL ARCHIVO OBTENIDO (Cortamos, retiramos lo innecesario, etc)
# Si se trata de un verbo, quitar las conjugaciones
id_conjugacion="<div id='conjugacion'>"
esunverbo=`grep -c "$id_conjugacion" ./"$palabra.html"`
if [ $esunverbo -gt 0 ]
then
echo "$palabra es un verbo" >> $f_verbos
# ELIMINAMOS la(s) CONJUGACIÓN(ES)
sed -i "/${id_conjugacion}/d" ./"$palabra.html"
fi
# Si tiene más de una acepción (Calcular cuántas después de saber si es un verbo)
id_acepcion="<article id="
id_acepcion_fin="<\/article>"
num_acepciones=`grep -c "$id_acepcion" ./"$palabra.html"`
# Si no tiene acepciones, la palabra no existe. No continuamos.
if [ $num_acepciones -eq 0 ]
then
echo "$palabra no se ha encontrado en la RAE" >> $f_errores
rm "./$palabra.html"
exit
fi
# PARTIR en $num_acepciones EL FICHERO $palabra.html"
# acepciones y acepciones_fin son 2 arrays de líneas PRECISO CONVERTIRLOS a cortes[]
acepciones=`grep -n "$id_acepcion" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones
do
let cortes[$c]=$(($i))
let c=$(($c+1))
done
acepciones_fin=`grep -n "$id_acepcion_fin" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones_fin
do
let cortes_fin[$c]=$(($i))
let c=$(($c+1))
done
# GENERA FICHEROS palabra.X.html por cada ACEPCIÓN
for (( i=0; i<$num_acepciones; i++ ))
do
# echo "El comienzo del corte está en ${cortes[$((i))]}"
# echo "El fin del corte está en ${cortes_fin[$((i))]}"
sed "${cortes[$((i))]},${cortes_fin[$((i))]} !d" "./$palabra.html" > "./$palabra.$i.html"
# Distintas salidas del programa, en función de la variable "salida"
if [ $salida -gt 0 ] # Salida a modo TXT
then
w3m "./$palabra.$i.html" > "./$palabra.$i.txt"
if [ $salida -gt 1 ] # En una sóla línea
then
sed ':a;N;$!ba;s/\n/ /g' "./$palabra.$i.txt"|sed 's/ / /g' > "./$palabra.$i.1linea"
fi
fi
done
# BORRAR indica si dejar o no los archivos que no se deseen como salida
BORRAR=1
if [[ $BORRAR -eq 1 ]] && [[ $salida -gt 0 ]]
then
rm "./$palabra."*html
if [ $salida -eq 2 ]
then
rm "./$palabra."*txt
fi
fi
# SALIDA FORZADA
exit
Este programa era invocado con el siguiente miniprogramita que, leyendo de la lista de palabras corregidas que, impropiamente, denominé diccionariosinrepes.txt, obtiene las diversas, impropiamente denominadas, acepciones y las separa en 90452 archivos de una única línea.
#!/bin/bash
### FUNCIONES ÚTILES PARA EL PROGRAMA
# uso() Instrucciones del programa y salida en caso de error.
uso () {
echo "Uso: $0 [diccionario]"
exit
}
# CONTROL DE ENTRADA DE VARIABLES y ASIGNACIÓN
if [ $# -gt 1 ]
then
# Reportar uso inapropiado
uso
elif [ $# -eq 1 ]
then
diccionario=$1
else
diccionario=diccionariosinrepes.txt
fi
while IFS= read -r line
do
buscaenrae.sh 2 $line
done < $diccionario
Descargadas y archivadas en una estructura de carpetas obvia:
dict -> LETRA
Se pueden reordenar o «recompilar» en una LETRA, con sus definiciones incluidas, sin incluir, etc…
Lo hago usando otro script simple:
#!/bin/bash
# El diccionario completo está por acepciones en las carpetas
# dict/LETRA
# Cada acepción (en realidad entrada en el diccionario) tiene
# un archivo denominado PALABRA.N.1linea conteniendo su definición.
# (donde N es el número de acepción contando desde cero)
letras="A B C D E F G H I J K L M N Ñ O P Q R S T U V W X Y Z"
for letra in $letras
do
ls dict/$letra > dictporletra/$letra.archivos.txt
awk -F"." '{print $1}' dictporletra/$letra.archivos.txt > dictporletra/$letra.acepciones.txt
ls dict/$letra/*.0.1linea |awk -F"/" '{print $3}'|awk -F"." '{print $1}' > dictporletra/$letra.sinrepes.txt
cat dict/$letra/* > dictporletra/$letra.definiciones.txt
done
cat dictporletra/*.archivos.txt > DICCIONARIO_TOTAL.archivos.txt
cat dictporletra/*.acepciones.txt > DICCIONARIO_TOTAL.acepciones.txt
cat dictporletra/*.sinrepes.txt > DICCIONARIO_TOTAL.sinrepes.txt
cat dictporletra/*.definiciones.txt > DICCIONARIO_TOTAL.definiciones.txt
Pero queda por resolver un problema que me tiene algo martirizado desde hace meses y es que la ordenación es muy compleja realizarla, pues muchas entradas en el diccionario son dobles, como «ad hoc», pero las definiciones descargadas incluyen líneas que son del tipo: «i Escrito con…» y desde el punto de vista del uso del comando sort, es más o menos lo mismo que decir que si quiero ordenar las primeras como «adhoc», la «iEscrito» se sale de su lugar.
He ordenado muchas manualmente sobre esta compilación, pero es un trabajo absolutamente aberrante y seguro que se puede hacer mejor, así que de momento he decidido dejar de trabajar en esto y dar por cerrado este proyecto que, en realidad, es la puerta de entrada a muchos otros.
Espero que el orden no sea algo tan terrible en esos otros proyectos venideros.
Estoy repasando los más de 1000 errores tipográficos que cometí durante la transcripción del diccionario de la RAE para el proyecto del diccionario personal de Isidoro Valcárcel Medina, pero me encuentro con que, además de los errores mencionados, ha habido desde entonces a hoy algunos cambios en la versión del DLE, como por ejemplo el de esta palabra que en la anterior edición (la vigésimo tercera), no existía con género masculino en ninguna de las acepciones, siendo así que «albandera» ha dejado de existir independientemente, para ser «albandero, ra», lo que no deja de ser un raro signo de error de ordenación alfabética, pues debiera ser «albandera, ro» y no tanto por una cuestión de visibilización, sino por el hecho de que en igualdad de condiciones, el diccionario se organiza tan sólo por orden frío y calculado de orden de letras… pero no parece ser el caso.
albendero, ra
1. m. y f. Persona que tejía o hacía albendas. 2. f. p. us. Mujer callejera y ociosa.
Por cierto, si un hombre es callejero y ocioso no tiene acepción que lo contemple.
Yo le respondí cortésmente con un email ese mismo día diciéndole:
Por supuesto eres libre de usarlo en un proyecto personal sin ánimo de lucro o, incluso, remunerado. Son las palabras de la RAE… es decir, de todos, que yo tan sólo he tecleado (ante la imposibilidad de conseguir una versión digital).
Puedes citarme como te dé la gana, pero agradecería que citases mi nombre y website:
Giusseppe Domínguez https://www.giusseppe.net
Te envío, no obstante, una entrada del blog con una versión lo más actualizada posible (en Mega) y no me responsabilizo de posibles errores… que voy corrigiendo, pero que seguro que alguna quedará. Si necesitas algún tipo de «sección» del mismo o alguna cosa curiosa… puedes decírmelo y si tengo ocasión, cuenta conmigo.
Un cordial saludo y hasta pronto,
Giusseppe
Fue muy bonito e interesante encontrarse en dónde había utilizado esas palabras y para qué: un análisis estadístico de las palabras en español, además de su gentileza a la hora de citarme en varios lugares agradeciéndome mi contribución (que siempre tiendo a minimizar, pues las palabras son públicas).
Buenas tardes, estimado Giusseppe,
Muchas gracias por su respuesta.
Le comparto el link a la página principal del proyecto en el que estoy trabajando, en donde realizo el agradecimiento a usted (en la sección Acknowledgment), con link a su website. https://ansegura7.github.io/DSL_Analysis/
También le comparto el resultado del análisis descriptivo en el que estoy trabajando. Agradecería sus comentarios al respecto. https://ansegura7.github.io/DSL_Analysis/pages/dsl_text_analysis.html
Próximamente, estaré compartiendo los resultados por Twitter. Por lo tanto, agradecería si me indica el nombre de usuario de su cuenta Twitter, para poder mencionarlo.
Una vez más, muchas gracias por compartir y recopilar el dataset del DLE.
Saludos cordiales,
Andrés Segura Tinoco
Me resulta simpático que llamen «dataset» al conjunto o listado de las palabras que recoge la RAE en su DLE. Los enlaces del proyecto de Andrés son fantásticos y es un trabajo divertido que seguro que además alguien considera útil.
Me alegra saber que te sirve el material recopilado.
He estado ojeando tu proyecto y tiene una pinta estupenda. Me encantan los análisis y tu codificación es muy limpia y bien comentada.
Como única sugerencia (no muy difícil de hacer) es la de escribir todas las frases del análisis en un array (o un archivo externo) que puede modificarse sencillamente para traducciones a otros idiomas. Me explico, por ejemplo, en la parte del código:
"source": [
"# Show results\n",
"n_words = len(word_dict)\n",
"print('Total of different words: %d' % n_words)"
]
podrías sustituir el print por algo así como:
"print('%s: %d' % msg_total_words[i], n_words)"
y tener un array de cadenas msg_total_words[LANGUAGES] o algo similar… (disculpa mi escaso conocimiento de python)
Es sólo una insignificante sugerencia que, seguramente, se puede hacer mejor que como te sugiero. (Leyendo los textos/mensajes de un archivo idiomático, por ejemplo)
Quizá me ha llamado la atención especialmente por el hecho de que no esté en español el resultado, lo que comprendo desde el punto de vista de la divulgación, pero también me resulta paradójico siendo que se habla sobre el español… 😉
Muchísimas gracias por la atribución y espero que no te molesten mis sugerencias.
Y en último agradecimiento, me escribió unos días después con los resultados que estaba obteniendo para hacerme partícipe de su publicación. (Lo que es de agradecer).
Estimado Giusseppe,
Muchas gracias por tu sugerencia. Me parece súper válida y útil para mayor y mejor divulgación del material publicado. La tendré en cuenta para este y futuros proyectos.
Aprovecho el correo y te comento 3 cosas brevemente:
1. Cree un hilo en Twitter publicando algunos de los resultados obtenidos en mi análisis y al final hay un tweet agradeciendo y reconociendo tu aporte con link directo a tu sitio web. Te comparto el enlace al hilo (son solo 8 tweets) por si los quieres revisar: https://twitter.com/seguraandres7/status/1298025632090259458?s=21
2. He hecho algunas correcciones sobre las palabras recopiladas. Encontré como 2 o 3 palabras en donde se acentuaban consonantes en vez de vocales y otros pequeños errores, en donde se invertían letras, sin embargo han sido menos de 10 correcciones hasta el momento. Una vez termine el proyecto, te envío de vuelta el diccionario de palabras, para que puedas actualizar el tuyo, de así considerarlo.
3. Para futuro networking o trabajos, te comparto mi sitio web y mi perfil de Twitter donde constantemente estoy publicando resultados de mis trabajos de investigación personales o académicos. Curiosamente, yo no tengo Facebook. Website: https://ansegura7.github.io/ y usuario de twitter: https://twitter.com/SeguraAndres7
Una vez mas, muchas gracias por recopilar y compartir este dataset tan valioso.
Saludos cordiales,
Andres Segura Tinoco
Telf: +57 3555590546
Actualicé mi diccionario con su revisión incorporada, para poder utilizarlo en nuevos proyectos, pero sé, soy consciente, que seguro que habrá más errores. Quizá por ello en el proyecto «Cocinillas» en el que estoy metido ahora mismo he querido incorporar un «testeador» o comprobador, para saber si la palabra que busco en el diccionario existe o no y, en caso contrario, hacer un listado con todas las palabras erróneas que tengo y poder mejorar mi diccionario en texto plano (aunque espero que la próxima vez que lo actualice pueda incorporar, incluso, todas las definiciones).
He fabricado un script (un lote de comandos) de bash shell en Linux para descargar y juguetear con búsquedas en la RAE, ya que resulta complicado pedir que tengan la deferencia de hacerla disponible para el público, como si la RAE fuese un organismo público pagado con dinero público.
Es el paso intermedio entre buscar una palabra y descargarme el diccionario completo palabra a palabra. Ahora toca hacer un pequeño programita que lo invoque para cada una de las palabras que tecleé para el proyecto de Isidoro Valcárcel Medina hace unos años y traiga sus definiciones.
Lo he llamado buscaenrae.sh.
Esta versión está modificada sobre la que publiqué hace unos días para subsanar errores relacionados con las palabras que contienen varias entradas/acepciones (no es lo mismo acepciones que entradas y soy consciente de ello, pero no es importante), así como para retirar las conjugaciones en los verbos.
#!/bin/bash
### FUNCIONES ÚTILES PARA EL PROGRAMA
# uso() Instrucciones del programa y salida en caso de error.
uso () {
echo "Uso: $0 salida palabra"
echo -e "\tsalida es un valor númerico que identifica:"
echo -e "\t[0] para generar un archivo HTML con la respuesta"
echo -e "\t[1] para generar un archivo TXT con la respuesta"
echo -e "\t[2] para generar una línea TXT con la respuesta"
exit
}
f_verbos="00000_VERBOS.txt"
f_errores="00000_ERRORES.txt"
# CONTROL DE ENTRADA DE VARIABLES y ASIGNACIÓN
if [ $# -lt 2 ]
then
# Reportar uso inapropiado
uso
else
salida=$1
if [ $# -eq 2 ]; then
palabra="$2"
elif [ $# -eq 3 ]; then
palabra="$2 $3"
elif [ $# -eq 4 ]; then
palabra="$2 $3 $4"
elif [ $# -eq 5 ]; then
palabra="$2 $3 $4 $5"
fi
# echo "Palabra es #$palabra#"
fi
# CONSULTA DEL SERVIDOR de la RAE simulando ser uno de los diversos navegadores posibles
navegador=(
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:77.0) Gecko/20100101 Firefox/77.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:77.0) Gecko/20190101 Firefox/77.0"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A"
)
rnd=`echo $(($RANDOM%${#navegador[@]}))` # Elegimos un navegador al azar
# Hacemos la petición a la web de la RAE
curl -s --user-agent "${navegador[$rnd]}" https://dle.rae.es/"$palabra" > ./"$palabra.html"
# PROCESAMOS EL ARCHIVO OBTENIDO (Cortamos, retiramos lo innecesario, etc)
# Si se trata de un verbo, quitar las conjugaciones
id_conjugacion="
"
esunverbo=`grep -c "$id_conjugacion" ./"$palabra.html"`
if [ $esunverbo -gt 0 ]
then
echo "$palabra es un verbo" >> $f_verbos
# ELIMINAMOS la(s) CONJUGACIÓN(ES)
sed -i "/${id_conjugacion}/d" ./"$palabra.html"
fi
# Si tiene más de una acepción (Calcular cuántas después de saber si es un verbo)
id_acepcion=""
num_acepciones=`grep -c "$id_acepcion" ./"$palabra.html"`
# Si no tiene acepciones, la palabra no existe. No continuamos.
if [ $num_acepciones -eq 0 ]
then
echo "$palabra no se ha encontrado en la RAE" >> $f_errores
rm "./$palabra.html"
exit
fi
# PARTIR en $num_acepciones EL FICHERO $palabra.html"
# acepciones y acepciones_fin son 2 arrays de líneas PRECISO CONVERTIRLOS a cortes[]
acepciones=`grep -n "$id_acepcion" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones
do
let cortes[$c]=$(($i))
let c=$(($c+1))
done
acepciones_fin=`grep -n "$id_acepcion_fin" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones_fin
do
let cortes_fin[$c]=$(($i))
let c=$(($c+1))
done
# GENERA FICHEROS palabra.X.html por cada ACEPCIÓN
for (( i=0; i<$num_acepciones; i++ ))
do
# echo "El comienzo del corte está en ${cortes[$((i))]}"
# echo "El fin del corte está en ${cortes_fin[$((i))]}"
sed "${cortes[$((i))]},${cortes_fin[$((i))]} !d" "./$palabra.html" > "./$palabra.$i.html"
# Distintas salidas del programa, en función de la variable "salida"
if [ $salida -gt 0 ] # Salida a modo TXT
then
w3m "./$palabra.$i.html" > "./$palabra.$i.txt"
if [ $salida -gt 1 ] # En una sóla línea
then
sed ':a;N;$!ba;s/\n/ /g' "./$palabra.$i.txt"|sed 's/ / /g' > "./$palabra.$i.1linea"
fi
fi
done
# BORRAR indica si dejar o no los archivos que no se deseen como salida
BORRAR=1
if [[ $BORRAR -eq 1 ]] && [[ $salida -gt 0 ]]
then
rm "./$palabra."*html
if [ $salida -eq 2 ]
then
rm "./$palabra."*txt
fi
fi
# SALIDA FORZADA
exit
Las primeras pruebas las he realizado con la palabra palabra, como debe ser.
Hoy he encontrado este texto en una red social que no me ha hecho sino recordar a cada palabra mi trabajo sobre La Consulta, en la que me hice esta misma pregunta, de manera algo existencial y pequeña: no «Los Artistas», sino «¿para qué sirvo (yo)?»
¿PARA QUÉ SIRVEN LOS ARTISTAS?
(Texto de Nacho Pata)
En términos prácticos no servimos para nada. Si alguien se enferma, o si a alguien se le descompone su coche o si tiene un problema legal, no llaman a un artista, sino a un doctor, un mecánico o a un abogado, nunca a un artista.
De hecho somos bastante inútiles ahora que lo pienso.
Cuando alguien nos pregunta a qué nos dedicamos, nunca tenemos una respuesta certera que satisfaga la curiosidad de quien nos pregunta, y menos aún si nos preguntan si podemos vivir de esto (en términos meramente económicos), cosa que tampoco podemos responder, ya que esa pregunta jamás se le hace abiertamente a un doctor, un mecánico o a un abogado, puesto que se da por hecho que les da suficiente para vivir y son profesiones incuestionables.
Entonces ¿para qué servimos? ¿Para qué sirve un pintor, un cineasta o un literato? ¿qué diablos gana la humanidad con un actor, un comediante o un músico? ¿en qué nos ayuda un escultor, un director de escena o un compositor? ¿Cómo resuelve nuestros problemas de vida alguien así?
¿De qué nos han servido Beethoven, Chava Flores, Akira Kurosawa, Pita Amor, Robert De Niro, Mario Benedetti, Vincent Van Gogh, Andi Warhol, Gustavo Cerati, Jaime Sabines, Pedro Almodóvar, David Alfaro Siqueiros, Roger Waters, Rockdrigo, Julio Jaramillo, Jodie Foster, Miguel Hernández, Los Beatles o hasta Juan Gabriel?
¿De qué servimos los músicos callejeros, los zanqueros, los clowns, los titiriteros, los cuenta cuentos, los fotógrafos, los mimos, los acróbatas los dibujantes y los actores?
Obviamente, para nada. Para nada práctico y mensurable. No podríamos arreglar ni una plancha, ni resolver un problema de crédito bancario.
Nuestra única función en esta vida es tocar los corazones y los pensamientos de la gente. Somos capaces de hacer reír o llorar, pensar o disfrutar a alguien sin tan siquiera tocarlo. Un cineasta o un actor te puede conmover hasta las lágrimas y un pintor o un fotógrafo te puede transportar en el tiempo, mientras que un clown o un escritor te puede hacer pensar al mismo tiempo que ríes o lloras. Un músico o un compositor te puede tocar y llenarte de tanta vida como un acróbata te puede sorprender de manera insospechada y marcar tu vida. Somos capaces de hacerte cuestionar sobre tu propia existencia mediante la belleza y la crudeza del arte.
No sé qué tan necesarios seamos, pero lo que sí sé es que la vida sería muy diferente sin nosotros, tal vez más aburrida, tal vez más autómata. Así pues, los artistas somos la representación más elaborada de la necesidad humana de expresión.
Nomás para eso servimos.
Hoy, sin embargo, me doy cuenta (si es que ya no me había dado cuenta antes) de que la pregunta está mal formulada y sale del esquema mental utilitarista en el que vivimos inmersos sin cuestionarlo en sí.
Es decir ¿tiene el arte que «servir para» algo?, debería ser la pregunta a formular.
Y aquí encuentro que acaba por decirse siempre que sí, por empatía o por algo abstracto indefinible, como el desarrollo personal o social de ahí que esté desbordándose el arte en forma de terapia o el arte como entretenimiento, ese arte que toca, que sirve… que es sirviente, en definitiva. Y no un arte empoderado, fuerte, que no busque servir ni ser servido, que sea independiente y libre de pensamiento, palabra y obra.
Por ende, nos gusta sentirnos incluidos en ese colectivo (olvidándonos hoy de géneros genéricos generosos) de «Los Artistas», como si fuésemos más elevados por ello, yo soy artista, claro que sí, yo soy poeta, claro que sí, yo soy performer, claro que sí, yo soy algo prestigioso, importante… que no importa a nadie en resumidas cuentas (porque de cuentas se trata) y no me da la economía para subsistir del arte, ni de la poesía, ni de nada similar, pero es por amor al arte y te ofrecen participar en un evento de arte de acción, para el que reservas tu tarde de sábado o de viernes y ni te planteas qué vas a cobrar por ello, ni que vas a cobrar por ello, así que te justificas diciendo que te puede dar visibilidad o curriculum… y sigues pensando con los mismos esquemas perversos que un consultor tecnológico, pero sin recibir el mismo salario ni por asomo.
Y si te alejas de ese «Los Artistas» para pensar en los demás, algo que no se ve todos los días, te das cuenta de que cualquier otra actividad se justifica desde ese mismo punto de vista: sirve o no sirve. Es productiva o no es productiva. Rinde o no rinde… y nunca «se rinde».
Porque la reflexión está mal vista. No sirve, sólo sirve la flexión, la genuflexión, la inflexión, como mucho.
«Eres demasiado reflexivo», «piensas demasiado», «los creí-ques y los pensé-ques son familia de don tonteque», «más acción y menos reflexión»…
Hay que hacer un arte útil, usable, popular, democrático… ya sea para la política, para la sociedad, para educarla, hacerla pensar, pero no demasiado, obligarla a pensar, de hecho, no vaya a ser que quiera pensar por su cuenta, un arte o una poesía al servicio de la protesta, pero nunca de la próstata, de la protesta simple y panfletaria, una poesía propagandística, un cine reivindicativo, una cultura solidaria, nunca solitaria… claro que sí, eso sí está bien visto, eso sí que es arte, no una atalaya de cristal, ni aunque sea de Murano.
Por eso en esa enumeración de artistas no encuentro afines, como Duchamp (Marcel), ni el kilo de mierda de artista de Manzoni, ni el vacío de Klein, ni la poesía concreta de Eduardo Scala, o el situacionismo de Guy Debord, ni, por supuesto, de mi gran referente personal, mi muy querido Isidoro Valcárcel Medina. La cultura. Esos grandes Torreznos que hicieron de ella una performance inolvidable.
Y vuelvo a mi círculo vicioso, viciado, enviciado y envicioso… ¿para qué sirvo (yo)? si es que sirvo para algo o, mejor aún… ¿y si no sirvo para nada, pasa algo? ¿debo remediarlo? ¿cómo ganarme la vida? ¿pero es que no tengo una vida? bueno, pues ¿cómo ganarme el pan?… o sea, que el pan ha de ser ganado con el sudor de mi frente, con el amasado sudoroso y cansado, con sangre, dolor y lágrimas, porque ser una cigarra es la condenación eterna. Porque hay que producir, producir, producir… o morir.