El 20 de agosto de este «peculiar» 2020 recibí un simpático correo electrónico de un hombre llamado «Germán Andrés Segura Tinoco» que me decía:
Buscando en Internet, encontré en su website el diccionario de la RAE en modo texto plano, el cual me pareció genial y quisiera usarlo en un proyecto personal (sin fines de lucro) y publicar el resultado en mi GitHub, en donde tengo mis proyectos de informática públicos.
Por lo tanto, quería preguntarle, ¿cuál es la forma correcta de citarlo o de darle agradecimientos?
No es la primera vez que me pasa algo así desde que realicé el trabajo de recopilar todas las palabras (tecleándolas) del diccionario de la RAE para aquel, lejano ya, proyecto de Isidoro Valcárcel Medina. Sin ir más lejos, el año pasado una persona desde Chile me decía que lo estaba usando para «enseñar a hablar» a una máquina. Así como la gran colaboración que realicé dentro del interesantísimo proyecto de Marta PCampos 1914-2014 sobre las palabras que habían desaparecido del diccionario en esos 100 años. Su precioso trabajo que yo denomino «Palabras Muertas».
Yo le respondí cortésmente con un email ese mismo día diciéndole:
Por supuesto eres libre de usarlo en un proyecto personal sin ánimo de lucro o, incluso, remunerado. Son las palabras de la RAE… es decir, de todos, que yo tan sólo he tecleado (ante la imposibilidad de conseguir una versión digital).
Puedes citarme como te dé la gana, pero agradecería que citases mi nombre y website:
Giusseppe Domínguez https://www.giusseppe.net
Te envío, no obstante, una entrada del blog con una versión lo más actualizada posible (en Mega) y no me responsabilizo de posibles errores… que voy corrigiendo, pero que seguro que alguna quedará. Si necesitas algún tipo de «sección» del mismo o alguna cosa curiosa… puedes decírmelo y si tengo ocasión, cuenta conmigo.
Un cordial saludo y hasta pronto,
Giusseppe
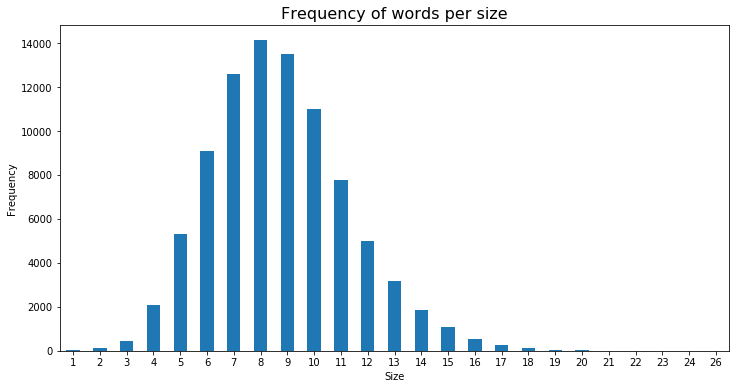
Fue muy bonito e interesante encontrarse en dónde había utilizado esas palabras y para qué: un análisis estadístico de las palabras en español, además de su gentileza a la hora de citarme en varios lugares agradeciéndome mi contribución (que siempre tiendo a minimizar, pues las palabras son públicas).
Buenas tardes, estimado Giusseppe,
Muchas gracias por su respuesta.
Le comparto el link a la página principal del proyecto en el que estoy trabajando, en donde realizo el agradecimiento a usted (en la sección Acknowledgment), con link a su website.
https://ansegura7.github.io/DSL_Analysis/
También le comparto el resultado del análisis descriptivo en el que estoy trabajando. Agradecería sus comentarios al respecto.
https://ansegura7.github.io/DSL_Analysis/pages/dsl_text_analysis.html
Próximamente, estaré compartiendo los resultados por Twitter. Por lo tanto, agradecería si me indica el nombre de usuario de su cuenta Twitter, para poder mencionarlo.
Una vez más, muchas gracias por compartir y recopilar el dataset del DLE.
Saludos cordiales,
Andrés Segura Tinoco
Me resulta simpático que llamen «dataset» al conjunto o listado de las palabras que recoge la RAE en su DLE. Los enlaces del proyecto de Andrés son fantásticos y es un trabajo divertido que seguro que además alguien considera útil.
En su proyecto mezclaba dos de mis grandes pasiones: la programación y el lenguaje, cosa que suelo hacer con frecuencia y que, próximamente, haré aún más. Así que estuve cotilleando con suma atención hasta que creí que podía hacerle una sugerencia útil, además de agradecerle su agradecimiento (entrando en un curioso bucle)
Me alegra saber que te sirve el material recopilado.
He estado ojeando tu proyecto y tiene una pinta estupenda. Me encantan los análisis y tu codificación es muy limpia y bien comentada.
Como única sugerencia (no muy difícil de hacer) es la de escribir todas las frases del análisis en un array (o un archivo externo) que puede modificarse sencillamente para traducciones a otros idiomas. Me explico, por ejemplo, en la parte del código:
"source": [
"# Show results\n",
"n_words = len(word_dict)\n",
"print('Total of different words: %d' % n_words)"
]
podrías sustituir el print por algo así como:
"print('%s: %d' % msg_total_words[i], n_words)"
y tener un array de cadenas msg_total_words[LANGUAGES] o algo similar… (disculpa mi escaso conocimiento de python)
Es sólo una insignificante sugerencia que, seguramente, se puede hacer mejor que como te sugiero. (Leyendo los textos/mensajes de un archivo idiomático, por ejemplo)
Quizá me ha llamado la atención especialmente por el hecho de que no esté en español el resultado, lo que comprendo desde el punto de vista de la divulgación, pero también me resulta paradójico siendo que se habla sobre el español… 😉
Muchísimas gracias por la atribución y espero que no te molesten mis sugerencias.
Un cordial saludo,
Giusseppe
PS: No uso Twitter. Tengo cuenta de Facebook e Instagram, just in case…
https://www.facebook.com/giusseppe.dominguez (perfil personal)
https://www.facebook.com/giusseppedelaaalaz (página «oficial»)
https://www.instagram.com/giusseppe.dominguez
Y en último agradecimiento, me escribió unos días después con los resultados que estaba obteniendo para hacerme partícipe de su publicación. (Lo que es de agradecer).
Estimado Giusseppe,
Muchas gracias por tu sugerencia. Me parece súper válida y útil para mayor y mejor divulgación del material publicado. La tendré en cuenta para este y futuros proyectos.
Aprovecho el correo y te comento 3 cosas brevemente:
1. Cree un hilo en Twitter publicando algunos de los resultados obtenidos en mi análisis y al final hay un tweet agradeciendo y reconociendo tu aporte con link directo a tu sitio web. Te comparto el enlace al hilo (son solo 8 tweets) por si los quieres revisar: https://twitter.com/seguraandres7/status/1298025632090259458?s=21
2. He hecho algunas correcciones sobre las palabras recopiladas. Encontré como 2 o 3 palabras en donde se acentuaban consonantes en vez de vocales y otros pequeños errores, en donde se invertían letras, sin embargo han sido menos de 10 correcciones hasta el momento. Una vez termine el proyecto, te envío de vuelta el diccionario de palabras, para que puedas actualizar el tuyo, de así considerarlo.
3. Para futuro networking o trabajos, te comparto mi sitio web y mi perfil de Twitter donde constantemente estoy publicando resultados de mis trabajos de investigación personales o académicos. Curiosamente, yo no tengo Facebook. Website: https://ansegura7.github.io/ y usuario de twitter: https://twitter.com/SeguraAndres7
Una vez mas, muchas gracias por recopilar y compartir este dataset tan valioso.
Saludos cordiales,
Andres Segura Tinoco
Telf: +57 3555590546
Actualicé mi diccionario con su revisión incorporada, para poder utilizarlo en nuevos proyectos, pero sé, soy consciente, que seguro que habrá más errores. Quizá por ello en el proyecto «Cocinillas» en el que estoy metido ahora mismo he querido incorporar un «testeador» o comprobador, para saber si la palabra que busco en el diccionario existe o no y, en caso contrario, hacer un listado con todas las palabras erróneas que tengo y poder mejorar mi diccionario en texto plano (aunque espero que la próxima vez que lo actualice pueda incorporar, incluso, todas las definiciones).