Podría resumirse en trabajo bien hecho, pero no sé si se ajusta la imprecisión de «bien» a lo que realicé instalando 2 servidores de ficheros linux en, casi, alta disponibilidad y resistencia a fallos, sincronizados, para una escuela de una compañía querida de teatro, llamada Residui.
Partíamos de un servidor (ubuntu 18) que usaban desde hacía décadas (sí, décadas) que había contenido windows que ya no usaban en dual boot, y funcionaba, pero claro, de cuando en cuando les daba sustos como el día en el que no arrancaba por un problema con el disco duro:
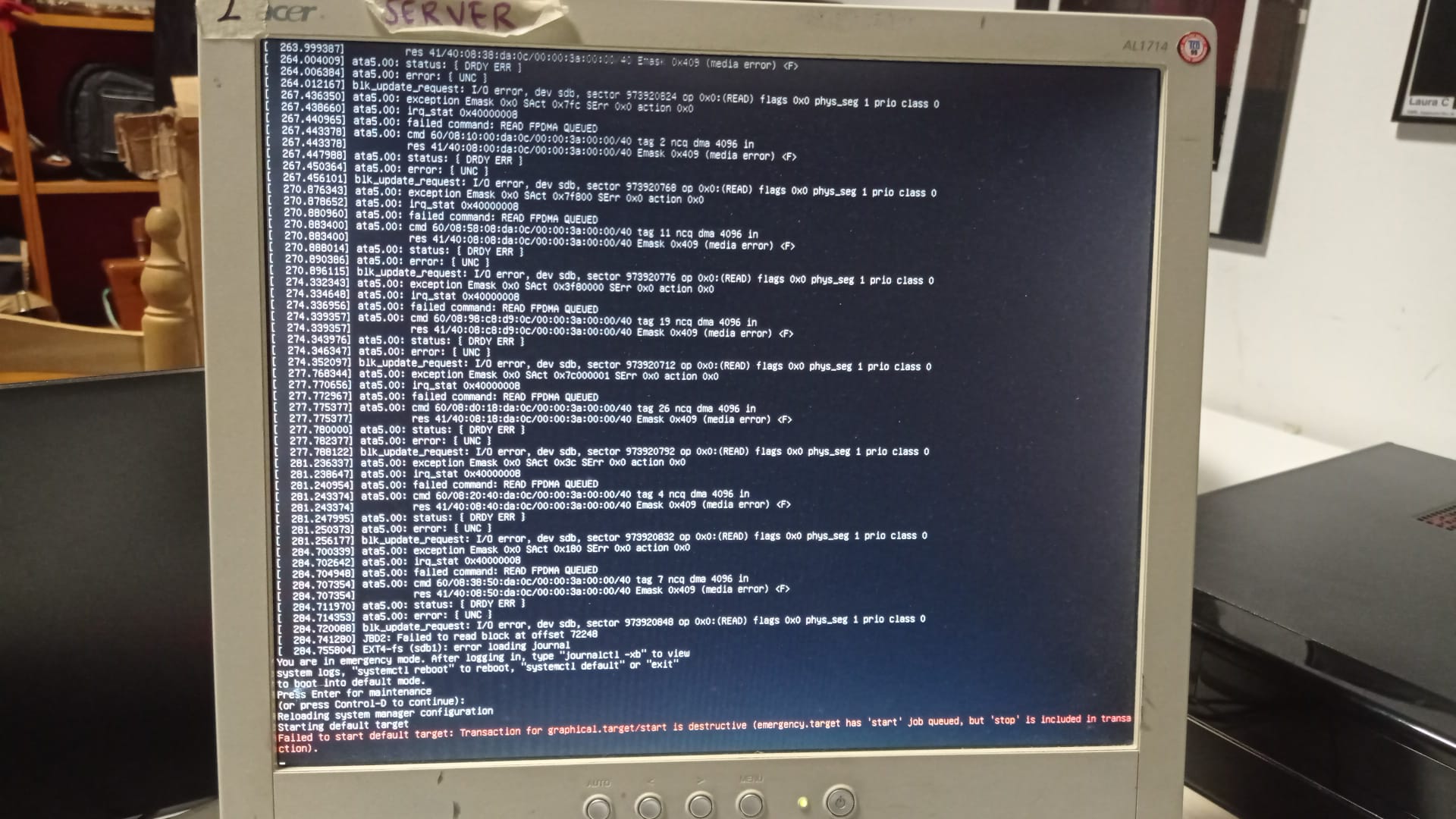
Era un equipo en el que había estado «metiendo mano» un montón de personas de manera desordenada, como viene siendo habitual en un entorno como este, de empresa minúscula que quiere gastar lo mínimo posible en esto, para poder dedicar su principal inversión a lo que verdaderamente hacen: Teatro.
Pero ya había llegado a un punto en el que el pobre chisme no daba más de sí. Y también lo necesitaban, así que les recomendé que compraran un segundo disco duro interno SATA (1Tb) como mínimo para incorporar a este PC (usado como servidor de ficheros con protocolo SAMBA/SMB).
Lo hicieron y me contrataron para reinstalar sistema operativo (iba terriblemente lento), borrar lo existente (menos sus datos compartidos), poner algo de orden y añadir el nuevo disco adquirido.
La placa SFF apenas tenía hueco para el disco incorporado, pero se pudo pegar al lateral de una de las paredes de la caja y quedó un poco chapucero pero funcionando por el mínimo precio posible.
Les avisé, no obstante, de que no me quedaba muy tranquilo, pues tener un único servidor y no hacer backups más que una vez cada año, aproximadamente, me parecía estar en la cuerda floja y son actores, no funambulistas.
Por fin, hace unos días, dado que el servidor les hacía mucho ruido, planteamos otra intervención, de nuevo, invirtiendo lo mínimo posible (otro disco duro interno de 2Tb) y un segundo PC que tenía mucho más espacio en la caja así como una placa muchísimo más moderna.

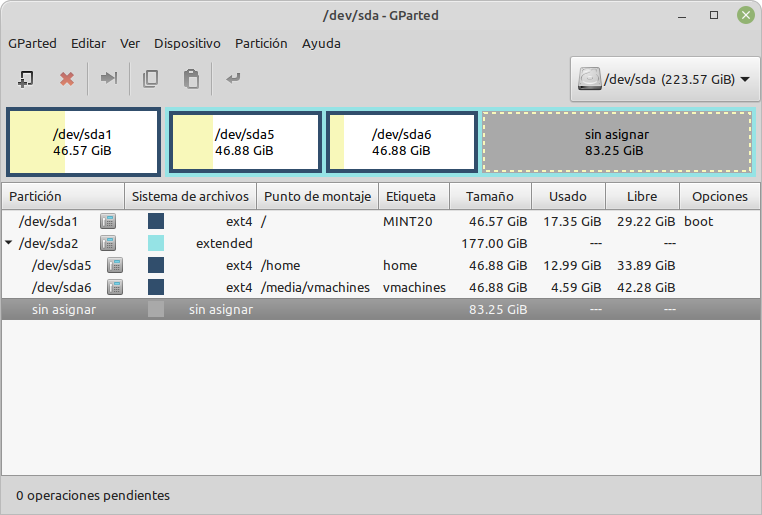
En esta situación, les he instalado el el segundo disco interno de 2Tb (DATOS1) y el que les pedí que comprasen para el antiguo servidor de 1Tb (DATOS2). Con esto, sin hacer muchas modificaciones a su linux mint 18 (que algún día tendrán que actualizar) y sin borrar las particiones que no usan de cuando en ese PC había instado un sistema operativo windows, tenían un flamante nuevo server (R1) en el que todo les funciona mucho mejor.
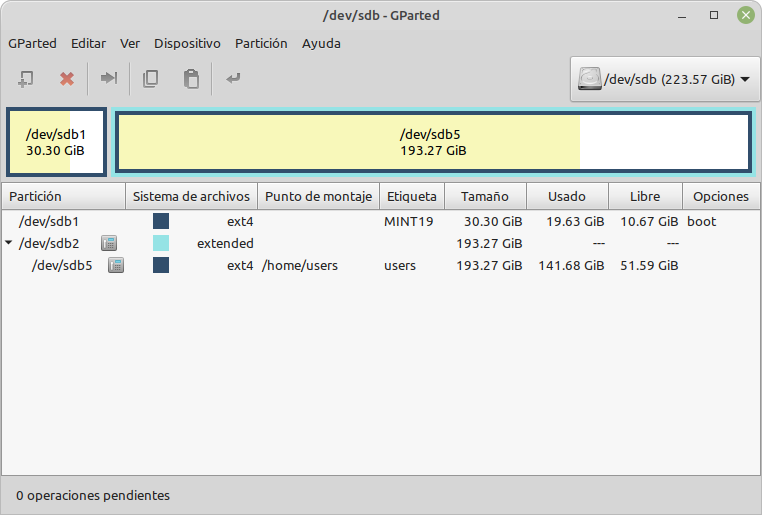
Pero aprovechando mi habilidad para recuperar cosas de trastos viejos, les dije que un antiguo portátil que tenían sin poder usar porque no funcionaba la fuente de alimentación, ni el conector de la corriente, contenía, sin embargo, un disco duro inutilizado que podíamos trasplantar a su antiguo server (R2). Con esto, teníamos en R2 dos discos duros, el interno de 1Tb (DATOS1) y el de 750Gb (DATOS2) que habíamos rescatado de aquel portátil para tirar.
Así, podíamos hacer un servidor de respaldo ante caídas inesperadas del R1, programando, además, una sincronización entre R1 y R2 con un rsync bastante sencillito, que replicase R1:/DATOS en R2:/DATOS para lo que tuve que configurar las conexiones SSH entre ambos equipos con sus claves públicas RSA intercambiadas.
Me quedé con una bonita sensación de satisfacción por haberles ahorrado todo el dinero posible y, al mismo tiempo, proporcionarles un sistema (2 equipos en alta disponibilidad) gastándonos lo mínimo, reciclando (reutilizando) recursos y, en la medida de lo posible, dándoles toda la autonomía necesaria para que no requieran mis servicios salvo muy puntualmente.
Sé que así no me haré rico, pero…